The progress in Artificial Intelligence or Machine Intelligence continues to be remarkable, now approaching human brain like levels of efficiency which is of course moving markets.
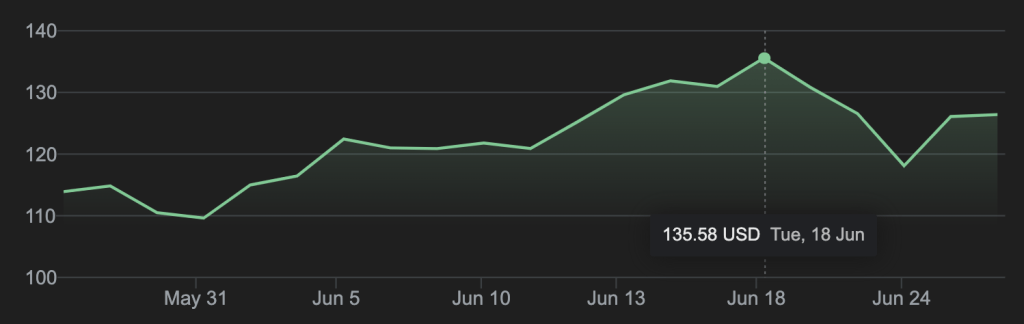
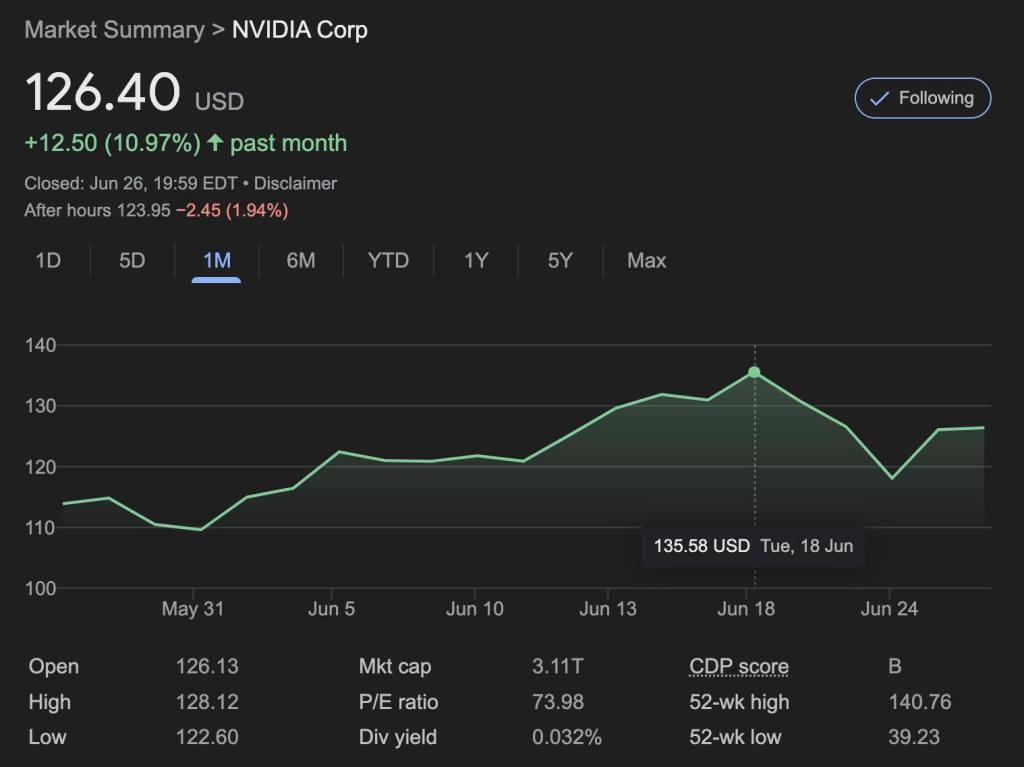
Just this one piece of research (its complex, so consider this a ‘non trivial read’ warning) appears to have at least indirectly impacted Nvidia (NVDA) share price to the tune of circa USD 300 BILLION when it was released on June 18 2024 just last week. More efficiency (actually 10x) clearly means less chip sales.
Obviously one group of researchers from Cornell University with connections around the world (no matter how smart they are) probably didn’t directly move the market but this is a big time for volatility in AI and tech generally. New competitors and new product announcements are an every day event.
NVDA is has been recently the largest company in the world by market capitalisation and is as such now firmly part of the Magnificent Seven tech stocks representing about 85-90% of the total tech sector at around USD 16 TRILLION with the market commentators saying it has never being more concentrated.
Or to put it another way, the top technology stocks market capitalisation in the US are now 4x the GDP of India which has 1.5 BILLION people.
You can read the full research here https://arxiv.org/abs/2406.02528 It is a bit of a heavy read so I asked another AI (Claude) to summarise below.
Editors Note: For our non-AI friends please please please do start to learn about this stuff now. It is impacting every part of every industry in remarkable ways. AI is here now and rather than fear AI changes and job losses we should learn and leverage daily everywhere. As our founder Pete Cooper says: AI is probably going to be bigger than the wheel, discovery of fire, the industrial age and the internet all combined.
————
The significance of this research on “Scalable MatMul-free Language Modeling” can be explained in 10 key points:
1. Computational Efficiency: By eliminating matrix multiplication, which is typically the most computationally expensive operation in LLMs, this approach could dramatically reduce the computational resources required for training and running these models.
2. Memory Reduction: The research demonstrates significant memory savings – up to 61% during training and over 10x during inference. This could make LLMs more accessible and deployable on a wider range of hardware.
3. Scalability: The study shows that their MatMul-free models can scale effectively up to at least 2.7B parameters, suggesting this approach could be viable for very large models.
4. Performance Parity: Despite removing matrix multiplications, these models achieve performance comparable to state-of-the-art Transformers at billion-parameter scales, indicating no significant loss in capability.
5. Narrowing Performance Gap: As model size increases, the performance gap between MatMul-free models and traditional Transformers narrows, suggesting this approach may be particularly valuable for very large models.
6. Hardware Efficiency: The researchers developed a custom FPGA implementation that achieved high throughput at very low power consumption (13W), moving towards brain-like efficiency for LLMs.
7. Future Hardware Implications: This work provides insights into the types of operations future AI accelerators should optimize for, potentially influencing the design of next-generation AI hardware.
8. Lightweight LLMs: By demonstrating how far LLMs can be simplified while maintaining effectiveness, this research opens up new possibilities for creating more efficient and accessible language models.
9. Practical Implementation: The researchers provide GPU-efficient implementations and custom hardware solutions, making their approach immediately applicable and testable by others in the field.
10. Broader Impact: This work could lead to more energy-efficient AI, reduced computational costs, and the ability to run powerful language models on a wider range of devices, potentially democratizing access to advanced AI technologies.
—–
Hat tip to our colleague Michael Kohl for putting Cooper & Co and all of Startup Samui onto this one. – Ed.
And to finish, a small potted history on why we call it Artificial Intelligence versus Machine Intelligence.
—–
The term “artificial intelligence” (AI) is more commonly used than “machine intelligence” for several reasons:
- Historical context: The term “artificial intelligence” was coined by John McCarthy in 1956 for the Dartmouth Conference, which is considered the founding event of AI as a field. The term has since become deeply ingrained in scientific and popular discourse.
- Emphasis on human creation: “Artificial” emphasizes that this intelligence is created by humans, distinguishing it from natural or biological intelligence.
- Broader scope: “Artificial” can encompass a wider range of intelligent systems, including software-based AI that doesn’t necessarily run on what we typically consider “machines.”
- Public understanding: The term “artificial intelligence” has become widely recognized and understood by the general public, partly due to its use in popular culture.
- Contrast with human intelligence: “Artificial” clearly distinguishes this type of intelligence from human intelligence, which is often the benchmark against which AI is measured.
However, “machine intelligence” is sometimes used, particularly in certain contexts:
- In discussions about embodied AI or robotics, where the intelligence is closely tied to a physical machine.
- When emphasizing the computational or hardware aspects of AI systems.
- In some academic or technical circles, to focus on the mechanistic nature of the intelligence.
Both terms essentially refer to the same concept, and the choice often comes down to context, tradition, and personal preference. The field continues to evolve, and terminology may shift over time as our understanding and implementation of AI systems progress.

